Brskalniki datotek Linux se obnašajo podobno kot File Explorer v operacijskem sistemu Windows ali Finder pod OS X, saj razvrščanje imenikov po velikosti ne deluje tako, kot bi pričakovali številni uporabniki. Imenike lahko razvrstite po številu podimenikov, ki jih vsebujejo, ali po številu datotek v njih. Kljub temu dejanska velikost datoteke v večini primerov ne deluje in boste potrebovali dodatno orodje.
Na srečo obstaja nekaj trikov, s katerimi lahko ugotovite dejansko velikost imenikov glede na količino zasedenega prostora v računalniku. Kar zadeva datotečne sisteme, je med mapami in imeniki zelo majhna razlika. Kar vaš brskalnik datotek imenuje mapa, je v resnici ista stvar, zato bodo ti triki delovali ne glede na to, katero besedo želite. Izraz imenik se uporablja zaradi doslednosti.
1. način: Razvrščanje imenikov z analizatorjem uporabe diska
Uporabniki Ubuntu, Debian in Linux Mint, ki imajo raje grafična orodja za analizo diska, bodo morda želeli poskusiti uporabiti sudo apt-get install baobab iz poziva. Uporabniki Fedore in Red Hat lahko na splošno uporabljajo sudo yum install baobab iz ukazne vrstice, vendar ne pozabite, da boste kot aplikacija GTK + morda morali izpolniti nekatere odvisnosti, če uporabljate namizno okolje, ki temelji na QT, kot sta KDE ali LXQT .
Ko ste vse zadovoljni, lahko aplikacijo zaženete iz ukazne vrstice, tako da vtipkate baobab, ali pa jo poiščete na pomišljaju na namizju Unbu Ubuntu. Lahko držite tipko Super ali Windows in pritisnete R, nato vtipkate baobab, če raje uporabljate program za iskanje aplikacij, ali pa ga zaženete tako, da kliknete meni Programi in poiščete GNOME Disk Usage Analyzer v kategoriji Sistemska orodja Vse je odvisno od tega, katero namizno okolje uporabljate.
Takoj, ko se zažene, vas bo baobab pozval, da izberete datotečni sistem. Izberite, katera naprava vsebuje imenik, ki ga iščete, in mu dajte nekaj trenutkov, da v njem naštejete strukturo imenikov. Ko se to zgodi, vam bo program predstavil vrsto vseh imenikov v napravi na najvišji ravni.
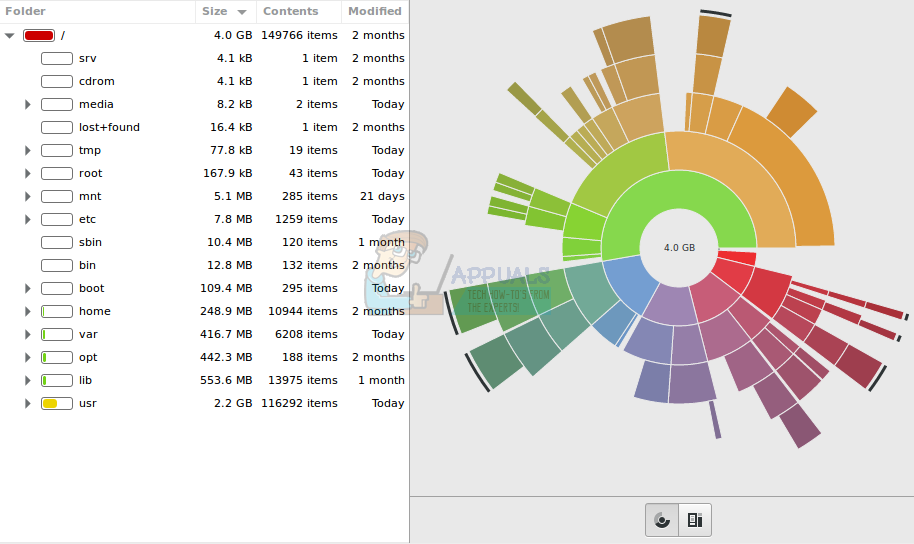
Lahko kliknete gumb Velikost, da razvrstite imenike od najvišjega do najnižjega glede na dejansko velikost, vendar je privzeto nasprotno. Kliknite puščice poleg imena imenika, da ga razširite in tako razvrstite podimenike, ki živijo pod njim.

S klikom na podnaslov Vsebina boste imenike dejansko razvrstili na enak način, kot to običajno počne upravitelj datotek, zato je to lahko koristno za primerjavo dejanske velikosti in velikega števila elementov, ki živijo v podimenikih vsakega najvišjega imenika.

2. metoda: Uporaba orodja Classic du
Orodje za uporabo diska (du) ukazne vrstice Unix lahko uporabite iz skoraj katerega koli poziva Linuxa, če ne želite delati v ukazni vrstici. Ta program bo povzel uporabo diska katerega koli nabora datotek. Če ga zaženete brez kakršnih koli argumentov, bo nadaljeval z rekurzivnim ogledom vsakega imenika in povzel velikost vsakega, dokler ne doseže konca drevesa.
Če predpostavimo, da bi raje razvrstili vsak imenik iz določenega odseka po njihovi velikosti, lahko uporabite naslednji ukaz:
du –si –max-depth = 1 nameOfDirectory | razvrsti -h
NameOfDirectory boste morali zamenjati z imenikom, v katerem bi najraje zagnali. Recimo, da ste na primer želeli razvrstiti vse imenike, ki so v neposredni bližini / lib, po velikosti. Ukaz lahko zaženete kot:
du –si –max-globina = 1 / lib | razvrsti -h
Številko boste morda želeli spremeniti po –max-depth =, saj ta vrednost določa, kako daleč v strukturi imenika naj išče ukaz du. Ker pa je bil cilj tukaj izogniti se iskanju po celotnem drevesu, smo se odločili, da ga pustimo na 1 in pogledamo pod en sam imenik.
Argument –si kaže, da bi moral ukaz du natisniti velikosti z uporabo Mednarodnega sistema enot, ki en kilobajt opredeli kot 1000 bajtov. Čeprav imajo to prednost tisti, ki so na Linux prešli iz OS X ali so navajeni izračunavati velikosti imenikov s strojno opremo, so mnogi uporabniki najbolj navajeni na binarne velikosti, kjer je 1.024 bajtov enako 1 megabajtu. Zamenjajte –si z -h, kot sledi:
du -h –max-globina = 1 / lib | razvrsti -h
Izhod bo prikazan po pričakovanjih, če imate raje binarne velikosti. Če ste navajeni meriti stvari v tako imenovanih kibibajtih, potem boste želeli uporabiti tudi ta ukaz. Morda boste želeli vključiti tudi | manj ali | več ukaza do konca te ukazne vrstice, če v imeniku najvišje ravni najdete toliko podimenikov, da izhod naraste takoj s strani. Ne pozabite, da bi se lahko z drsnikom, sledilno ploščico ali zaslonom na dotik lahko pomikali med rezultati v katerem koli sodobnem emulatorju terminala X.

Če se pogosto znajdete v uporabi te rešitve in si želite namesto tega imeti različico, zgrajeno na novih kletvah, potem lahko za namestitev ncurses uporabite sudo apt-get install ncdu v Debian, Ubuntu, različnih vrtljajih Ubuntu, Bodhi in Linux Mint- temelji na pregledovalniku. Uporabniki Fedore in Red Hat bi morali imeti možnost uporabe sudo yum install ncdu, če so nastavili datoteko sudoers, ali su - čemur sledi skrbniško geslo, čemur sledi yum install ncdu, če tega še niso storili.
Več kot verjetno se ne bi smeli soočiti z nobeno odvisnostjo, ker program temelji na ncurses in malo drugega. Zaženete ga lahko iz trenutnega imenika, tako da vnesete ncdu, ali pa pogledate drug del drevesa, tako da vnesete ncdu / lib ali kateri koli imenik, ki vas zanima.

Povedali boste, da programska oprema izračuna število elementov, ki jih je našla v zahtevanem imeniku. Ko končate, lahko s puščičnimi tipkami brskate po imenikih po vrstnem redu njihove resnične velikosti. Pritisnite tipko S, da razvrstite imenike naprej in nazaj po vrstnem redu velikosti.
4 minute branja